If you haven’t played around with Yahoo! Pipes, I highly recommend it. It’s a usable and useful service that brings web mashups to the masses, making this favorite hacker pastime as easy as dragging objects around on the screen.
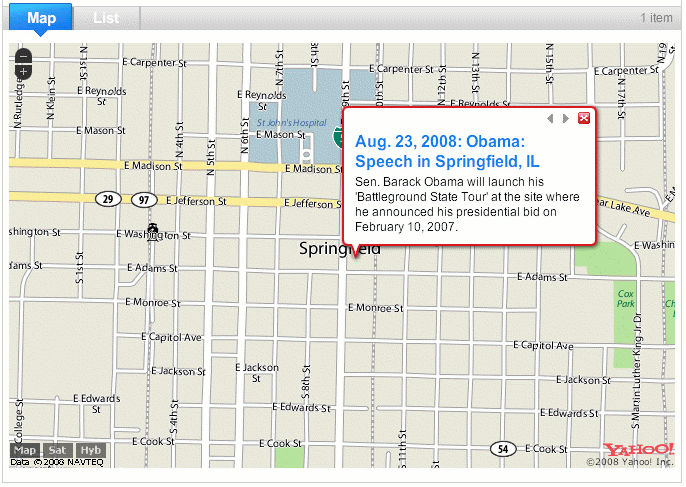
The easiest way to get started is to find an existing Pipe, clone it, and modify it as your own. Using this feature, I cloned my Obama map and in about one minute had a McCain map too.
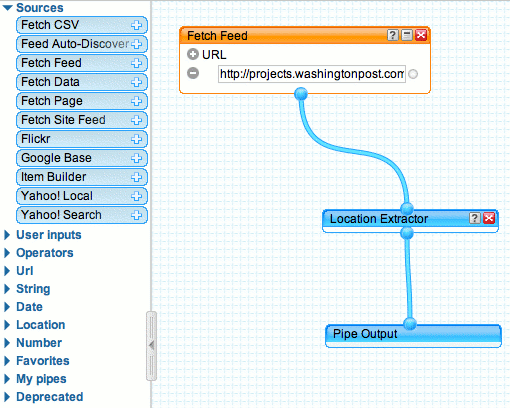
Pipes uses a visual programming interface. The idea of “programming by picture” (I recall playing with one in the 1980s) never took hold as a mainstream tool. However, as a metaphor for mashups, where to goal is to chain together a number of sources and services, the visual approach seems exactly right. The implementation in a browser is a feat of ajaxian magic that I still find remarkable, even as Yahoo! and others are commoditizing the art. I imagine that even non-programmers should have little trouble constructing their own Pipes. Here is a screenshot of the source “code” for my Obama map:
Pipes has dozens of useful modules, including user input, Yahoo! Search, Flickr, and regular expressions.
You can embed the Pipe on your own website with a single line of javascript. I did this with my Obama and McCain campaign travel maps here. Or you can grab the output as an XML feed to use however you wish.
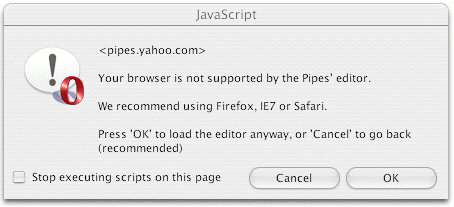
The icing on the cake for me is how Pipes — unlike so many other web sites, including some on Yahoo! — treats me and my Opera browser like adults:
(BTW, Pipes seems to work fine on Opera).
Unfortunately, Daniel Raffel, one of the key founders of Yahoo! Pipes, left Yahoo!. However, the team seems to be strong and continues to innovate, so I’m hopeful this fantastic service will continue to improve and thrive.
I joined the quantcast audience measurement service. It took about two minutes to sign up and initiate tracking. I’m impressed with the ease of use, the utility, and the inroads the company has made in the year or so since former Yahoo Mike Speiser first showed it to me.
I also joined the scribd document hosting service (“Youtube for documents”) and used it to embed a PDF in my previous post. Again, from signup to service took a matter of minutes. (I think scribd could be great for hosting my publications which are in need of both a content and interface update.)
Probably there’s some sort of business axiom here, probably already blogged and book-ed: the two minute rule of successful web services.
WeatherBill let’s you construct an enormous variety of insurance contracts related to weather. For example, the screenshot embedded below shows how I might have insured my vacation at the New Jersey shore:
For $42.62 I could have arranged to be paid $100 per day of rain during my vacation.
(I didn’t actually purchase this mainly because the US government insists that I am a menace to myself and should not be allowed to enter into such a dangerous gamble — more on this later. And as Dan Reeves pointed out to me, it’s probably not rational to do for small sums.)
WeatherBill is an example of the evolution of financial exchanges as they embrace technology.
WeatherBill can be thought of as expressive insurance, a financial category no doubt poised for growth and a wonderful example of how computer science algorithms are finally supplanting the centuries-old exchange logic designed for humans (CombineNet is another great example).
WeatherBill can also be thought of as a combinatorial prediction market with an automated market maker, a viewpoint I’ll expand on now.
On WeatherBill, you piece together contracts by specifying a series of attributes: date range, place, type of weather, threshold temperature or participation level, minimum and maximum number of bad-weather days, etc. The user interface is extremely well done: a straightforward series of adaptive menu choices and text entry fields guide the customer through the selection process.
This flexibility quickly leads to a combinatorial explosion: given the choices on the site I’m sure the number of possible contracts you can construct runs into the millions.
Once you’ve defined when you want to be paid — according to whatever definition of bad weather makes sense for you or your business — you choose how much you want to be paid.
Finally, given all this information, WeatherBill quotes a price for your custom insurance contract, in effect the maximum amount you will lose if bad weather doesn’t materialize. Quotes are instantaneous — essentially WeatherBill is an automated market maker always willing to trade at some price on any of millions of contracts.
Side note: On WeatherBill, you control the magnitude of your bet by choosing how much you want to be paid. In a typical prediction market, you control magnitude by choosing how many shares to trade. In our own prediction market Yoopick, you control magnitude by choosing the maximum amount you are willing to lose. All three approaches are equivalent, and what’s best depends on context. I would argue that the WeatherBill and Yoopick approaches are simpler to understand, requiring less indirection. The WeatherBill approach seems most natural in an insurance context and the Yoopick approach in a gambling context.
How does the WeatherBill market maker determine prices? I don’t know the details, but their FAQ says that prices change “due to a number of factors, including WeatherBill forecast data, weather simulation, and recent Contract sales”. Certainly historical data plays an important role — in fact, with every price quote WeatherBill tells you what you would have been paid in years past. They allow contracts as few as four days into the future, so I imagine they incorporate current weather forecasts. And the FAQ implies that some form of market feedback occurs, raising prices on contract terms that are in high demand.
Interface is important. WeatherBill shows that a very complicated combinatorial market can be presented in a natural and intuitive way. Though greater expressiveness can mean greater complexity and confusion, Tuomas Sandholm is fond of pointing out that, when done right, expressiveness actually simplifies things by allowing users to speak in terms they are familiar with. WeatherBill — and to an extent Yoopick IMHO — are examples of this somewhat counterintuitive principle at work.
There is another quote from WeatherBill’s FAQ that alludes to an even higher degree of combinatorics coming soon:
Currently you can only price contracts based on one weather measurement. We’re working on making it possible to use more than one measurement, and hope to make it available soon.
If so, I can imagine the number of possible insurance contracts quickly growing into the billions or more with prices hinging on interdependencies among weather events.
Finally, back to the US government treating me like a child. It turns out that only a very limited set of people can buy contracts on WeatherBill, mainly businesses and multi-millionaires who aren’t speculators. In fact, the rules of who can play are a convoluted jumble that I believe are based on regulations from the US Commodity Futures Trading Commission.
Luckily, WeatherBill provides a nice “choose your own adventure” style navigation flow to determine whether you are allowed to participate. Most people will quickly find they are not eligible. (I don’t officially endorse the CYOA standard of re-starting over and over again until you pass.)
Even if red tape locks the average consumer out of direct access, clever companies are stepping in to mediate. In a nice intro piece on WeatherBill, Newsweek mentions that Priceline used WeatherBill to back a “Sunshine Guaranteed” promotion offering refunds to customers whose trips were rained out.
Can you think of other end-arounds to bring WeatherBill functionality to the masses? What other forms of expressive insurance would you like to see?
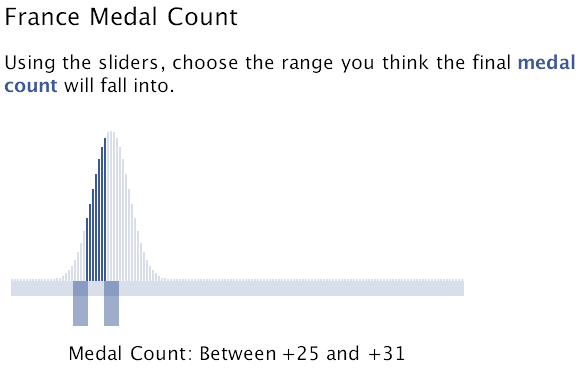
We just added a new feature to Yoopick designed especially for Frenchmen Chris and Emile and citizens of nineteen other countries to place their swagor* on how many Olympic medals they think their country will win.
We’ve argued that the Yoopick interface is useful for predicting almost any kind of number, and since medal count is indeed a number, we thought we’d give it a try.
I mostly side with Lukas and Panos on the fantastic potential of Amazon’s Mechanical Turk, a crowdsourcing service specializing in tiny payments for simple tasks that require human brainpower, like labeling images. Within the field of computer science alone, this type of service will revolutionize how empirical research is done in communities from CHI to SIGIR, powering unprecedented speed and scale at low cost (here are twoexamples). My guess is that the impact will be even larger in the social sciences; already, a number of folks in Yahoo’s Social Dynamics research group have started running studies on mturk. (A side question is how university review boards will react.)
However there is a seedier side to mturk, and I’m of two minds about it. Some people use the service to hire sockpuppets to enter bogus ratings and reviews about their products and engage in other forms of spam. (Actually this appears to violate mturk’s stated policies.)
For example, Samuel Deskin is offering up to ten cents to turkers willing to promote his new personalized start page samfind.
EARN TEN CENTS WITH THE BONUS – EASY MONEY – JUST VOTE FOR US AND COMMENT ABOUT US
EARN FOUR CENTS IF YOU:
1. Set up an anoymous email account likke gmail or yahoo so you can register on #2 anonymously
2. Visit http://thesearchrace.com/signup.php and sign up for an account – using your anonymous email account.
3. Visit http://www.thesearchrace.com/recent.php and vote for:
samfind
By clcking “Pick”
SIX CENTS BONUS:
4. Visit the COMMENTS Page on The Search Race, it is the Button Right Next to “Picks” on this page: http://www.thesearchrace.com/recent.php and
5. Say something awesome about samfind (http://samfind.com) on The Search Race’s Comments page.
Make sure to:
1. Tell us that you Picked us.
2. Copy and Paste the Comment you typed on The Search Race’s Comment page here so we know you wrote it and we will give you the bonus!
Another type of task on mturk involves taking a piece of text and paraphrasing it so that the words are different but the meaning remains the same. Here is an example:
Paraphrase This Paragraph
Here’s the original paragraph:
You’re probably wondering how to apply a wrinkle filler to your skin. The good news is that it’s easy! There are a number of different products on the market for anti aging skin care. Each one comes with its own special application instructions, which you should always make sure to read and carefully follow. In general, however, most anti aging skin care products are simply applied to the skin and left to soak in.
Requirements:
1. Use the same writing style as much as possible.
2. Vary at least 50% of the words and phrases – but keep the same concepts. Use obviously different sentences! Your paragraph should not be just a copy of the first with a few word replacements.
3. Any keywords listed in bold in the above paragraph must be included in your paraphrase.
4. The above paragraph contains 75 words… yours must contain at least 64 words and not more than 101 words.
5. Write using American English.
6. No obvious spelling or grammar mistakes. Please use a spell-checker before submitting. A free online spell checker can be found at www.spellcheck.net.
If you find it easier to paraphrase sentence-by-sentence, then do that. Please do not enter anything in the textbox other than your written paragraph. Thanks!
I have no direct evidence, but I imagine such a task is used to create splogs (I once found what seems like such a “paraphrasing splog”), ad traps, email spam, or other plagiarized content.
It’s possible that paid spam is hitting my blog (either that or I’m overly paranoid). I’m beginning to receive comments that are almost surely coming from humans, both because they clearly reference the content of the post and because they pass the re-captcha test. However, the author’s URL seems to point to an ad trap. I wonder if these commenters (who are particularly hard to catch — you have to bother to click on the author URL) are paid workers of some crowdsourcing service?
Can and should Amazon try to filter away these kinds dubious uses of Mechanical Turk? Or is it better to have this inevitable form of economic activity out in the open? One could argue that at least systems like mturk impose a tax on pollution and spam, something long argued as an economic force to reduce spam.
My main objection to these activities is the lack of disclosure. Advertisements and press releases are paid for, but everyone knows it, and usually the funding source is known. However, the ratings, reviews, and paraphrased text coming out of mturk masquerade as authentic opinions and original content. I absolutely want mturk to succeed — it’s an innovative service of tremendous value, one of many to come out of Amazon recently — but I believe Amazon is risking a minor PR backlash by allowing these activities to flow through its servers and by profiting from them.
Musings of a computer scientist on predictions, odds, and markets