What is a better investment objective?
- Grow as wealthy as possible as quickly as possible, or
- Maximize expected wealth for a given time period and level of risk
The question is at the heart of a fight between computer scientists and economists chronicled beautifully in the book Fortune’s Formula by Pulitzer Prize nominee William Poundstone. (See also David Pogue’s excellent review.*) From the book’s sprawling cast — Claude Shannon, Rudy Giuliani, Michael Milken, mobsters, and mob-backed companies (including what is now Time Warner!) — emerges an unlikely duel. Our hero, mathematician turned professional gambler and investor Edward Thorp, leads the computer scientists and information theorists preaching and, more importantly, practicing objective #1. Nobel laureate Paul Samuelson (who, sadly, recently passed away) serves as lead villain (and, to an extent, comic foil) among economists promoting objective #2 in often patronizing terms. The debate sank to surprisingly depths of immaturity, hitting bottom when Samuelson published an economist-peer-reviewed article written entirely in one-syllable words, presumably to ensure that his thrashing of objective #1 could be understood by even its nincompoop proponents.
Objective #1 — The Kelly criterion
Objective #1 is the have-your-cake-and-eat-it-too promise of the Kelly criterion, a money management formula first worked out by Bernoulli in 1738 and later rediscovered and improved by Bell Labs scientist John Kelly, proving a direct connection between Shannon-optimal communication and optimal gambling. Objective #1 matches common sense: who wouldn’t want to maximize growth of wealth? Thorp, college professor by day and insanely successful money manager by night, is almost certainly the greatest living example of the Kelly criterion at work. His track record is hard to refute.
Investing according to the Kelly criterion achieves objective #1. The strategy provably maximizes the growth rate of wealth. Stated another way, it minimizes the time it takes to reach any given aspiration level, say $1 million, or your desired sized nest egg for retirement. If two twins with equal initial wealth were to invest long enough, one according to Kelly and the other not, the Kelly twin would finish richer with 100% certainty.
Objective #2
Objective #2 refers to standard economic dogma. Low-risk/high-return investments are always preferred to high-risk/low-return investments, but high-risk/high-return and low-risk/low-return are not comparable in general. Deciding between these is a personal choice, a function of the decision maker’s risk attitude. There is no optimal portfolio, only an efficient frontier of many Pareto optimal portfolios that trade off risk for return. The investor must first identify his utility function (how much he values a dollar at every level of wealth) in order to compute the best portfolio among the many valid choices. (In fact, objective #1 is a special case of #2 where utility for money is logarithmic. Deriving rather than choosing the best utility function is anathema to economists.)
Objective #2 is straightforward for making one choice for a fixed time horizon. Generalizing it to continuous investment over time requires intricate forecasting and optimization (which Samuelson published in his 1969 paper “Lifetime portfolio selection by dynamic stochastic programming”, claiming to finally put to rest the Kelly investing “fallacy” — p.210). The Kelly criterion is, astonishingly, a greedy (myopic) rule that at every moment only needs to worry about figuring the current optimal portfolio. It is already, by its definition, formulated for continuous investment over time.
Details and Caveats
There is a subtle and confusing aspect to objective #1 that took me some time and coaching from Sharad and Dan to wrap my head around. Even though Kelly investing maximizes long-term wealth with 100% certainty, it does not maximize expected wealth! The proof of objective #1 is a concentration bound that appeals to the law of large numbers. Wealth is, eventually, an essentially deterministic quantity. If a billion investors played non-Kelly strategies for long enough, then their average wealth might actually be higher than a Kelly investor’s wealth, but only a few individuals out of the billion would be ahead of Kelly. So, non-Kelly strategies can and will have higher expected wealth than Kelly, but with probability approaching zero. Note that, while Kelly does not maximize expected (average) wealth, it does maximize median wealth (p.216) and the mode of wealth. See Chapter 6 on “Gambling and Data Compression” (especially pages 159-162) in Thomas Cover’s book Elements of Information Theory for a good introduction and concise proof.
Objective #1 does have important caveats, leading to legitimate arguments against pure Kelly investing. First, it’s often too aggressive. Sure, Kelly guarantees you’ll come out ahead, but only if investing for “long enough”, a necessarily vague phrase that could mean, well, infinitely long. (In fact, a pure Kelly investor at any time has a 1 in n chance of losing all but 1/n of their wealth — p.229) The guarantee also only applies if your estimate of expected return per dollar is accurate, a dubious assumption. So, people often practice what is called fractional Kelly, or investing half or less of whatever the Kelly criterion says to invest. This admittedly starts down a slippery slope from objective #1 to objective #2, leaving the mathematical high ground of optimality to account for people’s distaste for risk. And, unlike objective #2, fractional Kelly does so in a non-principled way.
Even as Kelly investing is in some ways too aggressive, it is also too conservative, equating bankruptcy with death. A Kelly strategy will never risk even the most minuscule (measure zero) probability of losing all wealth. First, the very notion that each person’s wealth equals some precise number is inexact at best. People hold wealth in different forms and have access to credit of many types. Gamblers often apply Kelly to an arbitrary “casino budget” even though they’re an ATM machine away from replenishment. People can recover nicely from even multiple bankruptcies (see Donald Trump).
Some Conjectures
Objective #2 captures a fundamental trade off between expected return and variance of return. Objective #1 seems to capture a slightly different trade off, between expected return and probability of loss. Kelly investing walks the fine line between increasing expected return and reducing the long-run probability of falling below any threshold (say, below where you started). There are strategies with higher expected return but they end in ruin with 100% certainty. There are strategies with lower probability of loss but that grow wealth more slowly. In some sense, Kelly gets the highest expected return possible under the most minimal constraint: that the probability of catastrophic loss is not 100%. [Update 2010/09/09: The statements above are not correct, as pointed out to me by Lirong Xia. Some non-Kelly strategies can have higher expected return than Kelly and near-zero probability of ruin. But they will do worse than Kelly with probability approaching 1.]
It may be that the Kelly criterion can be couched in the language of computational complexity. Let Wt be your wealth at time t. Kelly investing grows expected wealth exponentially, something like E[Wt] = o(xt) for x>1. It simultaneously shrinks the probability of loss, something like Pr(Wt< T) = o(1/t). (Actually, I have no idea if the decay is linear: just a guess.) I suspect that relaxing the second condition would not lead to much higher expected growth, and perhaps that fractional Kelly offers additional safety without sacrificing too much growth. If formalized, this would be some sort of mixed Bayesian and worst-case argument. The first condition is a standard Bayesian one: maximize expected wealth. The second condition — ensuring that the probability of loss goes to zero — guarantees that even the worst case is not too bad.
Conclusions
Fortune’s Formula is vastly better researched than your typical popsci book: Poundstone extensively cites and quotes academic literature, going so far as to unearth insults and finger pointing buried in the footnotes of papers. Pounstone clearly understands the math and doesn’t shy away from it. Instead, he presents it in a detailed yet refreshingly accessible way, leveraging fantastic illustrations and analogies. For example, the figure and surrounding discussion on pages 197-201 paint an exceedingly clear picture of how objectives #1 and #2 compare and, moreover, how #1 “wins” in the end. There are other gems in the book, like
- Kelly’s quote that “gambling and investing differ only by a minus sign” (p.75)
- Louis Bachelier’s discovery of the efficient market hypothesis in 1900, a development that almost no one noticed until after his death (p.120)
- Poundstone’s assertion that “economists do not generally pay much attention to non-economists” (p.211). The assertion rings true, though to be fair applies to most fields and I know many glaring exceptions.
- The story of the 1998 collapse of Long-Term Capital Management and ensuing bailout is sadly amusing to read today (p.290). The factors are nearly identical to those leading to the econalypse of 2008: leverage + correlation + too big to fail. (Poundstone’s book was published in 2005.) Will we ever learn? (No.)
Fortune’s Formula is a fast, fun, fascinating, and instructive read. I highly recommend it.
__________
* See my bookmarks for other reviews of the book and some related research articles.
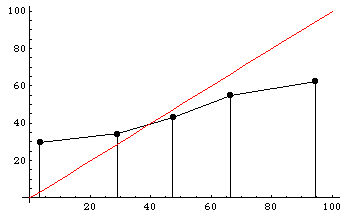 Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.
Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.