Until just reading about it in Wired, I knew little1 of the apparent suicide of Push Singh, a rising star in the field of artificial intelligence.
Singh seemed to have everything going for him: brilliant and driven, he became the protégé of his childhood hero Marvin Minsky, eventually earning a faculty position alongside him at MIT. Professionally, Singh earned praise from everyone from IEEE Intelligent Systems, who named Singh one of AI’s Ten to Watch (apparently revised), to Bill Gates, who asked Singh to keep him appraised of his latest publications. Singh’s social life seemed healthy and happy. The article struggles to uncover a hint of why Singh would take his own life, mentioning his excruciating chronic back pain (and linking it to a passage on the evolutionary explanation of pain as “programming bug” in Minsky’s new book, a book partly inspired by Singh).
The article weaves Push’s story with the remarkable parallel life and death of Chris McKinstry, a man with similar lofty goals of solving general AI, and even a similar approach of eliciting common sense facts from the public. (McKinstry’s Mindpixel predated Singh’s OpenMind initiative.) McKinstry’s path was less socially revered, and he seemed on a never ending and aching quest for credibility. The article muses whether there might be some direct or indirect correlation between the eerily similar suicides of the two men, even down to their methods.
For me, the story felt especially poignant, as growing up I was nourished on nearly the same computer geek diet as Singh: Vic 20, Apple II, Star Trek, D&D, HAL 9000, etc. In Singh I saw a smarter and more determined version of myself. Like many, I dreamt of solved AI, and of solving AI, even at one point wondering if a neural network trained on yes/no questions might suffice, the framework proposed by McKinstry. My Ph.D. is in artificial intelligence, though like most AI researchers my work is far removed from the quest for general AI. Over the years, I’ve become at once disillusioned with the dream2 and, hypocritically, upset that so many in the field have abandoned the dream in pursuit of a fractured set of niche problems with questionable relevance to whole.
Increasingly, researchers are calling for a return to the grand challenge of general AI. It’s sad that Singh, one of the few people with a legitimate shot at leading the way, is now gone.
| 1Apparently details about Singh’s death have been slow to emerge, with MIT staying mostly quiet, for example not discussing the cause of death and taking down a memorial wiki built for Singh. | |
| 1 My colleague Fei Sha, a new father, put it nicely, saying he is “constantly amazed by the abilities of children to learn and adapt and is losing bit by bit his confidence in the romantic notion of artificial intelligence”. |
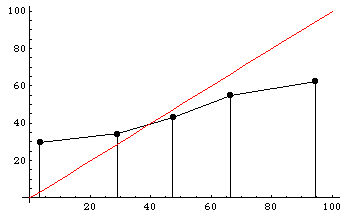 Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.
Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.