I just left the 2010 ACM Conference on Electronic Commerce, where six (!) out of 45 papers were about prediction markets.
Yahoo! Lab’s own Predictalot market is now live and waiting for you to place almost any prediction your heart desires about the World Cup in South Africa.
Here are some terribly useful things you can learn this time around. All numbers are subject to change, and that’s kind of the point:
There’s a 37% chance Brazil and Spain will both make it to the final game; there’s only a 15% chance that neither of them will make it
There’s is a 1 in 25 chance Portugal will win the cup; 1 in 50 for Argentina
42.92% chance that a country that has never won before will win
19.07% chance that Australia will advance further than England
65.71% chance that Denmark, Italy, Mexico and United States all will not advance to Semifinals
If you think these odds are wrong, place your virtual wager and earn some intangible bragging rights. You can sell your prediction any time for points, even in the middle of a match, just like the stock market.
There are millions of predictions available, yet I really believe ours is the simplest prediction market interface to date. (Do you disagree, Leslie?) We have an excellent conversion rate, or percent of people who visit the site who go on to place at least one prediction — for March Madness, that rate was about 1 in 5. One of our main goals was to hide the underlying complexity and make the app fast, easy, and fun to use. I personally am thrilled with the result, but please go judge for yourself and tell us what you think.
In the first version of Predictalot, people went well beyond picking the obvious like who will win. For example, they created almost 4,000 “three-dimensional” predictions that compared one team against two others, like “Butler will advance further than Kentucky and Purdue”.
If you’re not sure what to predict, you can now check out the streaming updates of what other people are predicting in your social circle and around the world:
Also new this time, you can join a group and challenge your friends. You can track how you stack up in each of your groups and across the globe. We now provide live match updates right within the app for your convenience.
If you have the Yahoo! Toolbar (if not, try the World Cup toolbar), you can play Predictalot directly from the toolbar without leaving the webpage you’re on, even if it’s Google. 😉
Bringing Predictalot to life has been a truly interdisciplinary effort. On our team we have computer scientists and economists to work out the market math, and engineers to turn those equations into something real that is fast and easy to use. Predictalot is built on the Yahoo! Application Platform, an invaluable service (open to any developer) that makes it easy to make engaging and social apps for a huge audience with built-in distribution. And we owe a great deal to promotion from well-established Yahoo! properties like Fantasy Sports and Games.
We’re excited about this second iteration of Predictalot and hope you join us as the matches continue in South Africa. We invite everyone to join, though please do keep in mind that the game is in beta, or experimental, mode. (If you prefer a more polished experience, check out the official Yahoo! Fantasy Sports World Soccer game.) We hope it’s both fun to play and helps us learn something scientifically interesting.
In September 2007 I predicted that “Google [will buy] a TV ad for Google.com aimed at mass consumers  before September 2008. I only missed it by a year and a half.
Confession: In this post I am guilty of exactly the sins I’ve complained about in the past: cherry picking positive outcomes in hindsight, and measuring probabilistic predictions categorically and in isolation. Oops.
Quantifying New York’s 2009 June gloom using WeatherBill and Wolfram|Alpha
In the northeastern United States, scars are slowly healing from a miserably rainy June — torturous, according to the New York Times. Status updates bemoaned “where’s the sun?”, “worst storm ever!”, “worst June ever!”. Torrential downpours came and went with Florida-like speed, turning gloom into doom: “here comes global warming”.
But how extreme was the month, really? Was our widespread misery justified quantitatively, or were we caught in our own self-indulgent Chris Harrisonism, “the most dramatic rose ceremony EVER!”.
This graphic shows that, as of June 20th, New York City was on track for near-record rainfall in inches. But that graphic, while pretty, is pretty static, and most people I heard complained about the number of days, not the volume of rain.
I wondered if I could use online tools to determine whether the number of rainy days in June was truly historic. My first thought was to try Wolfram|Alpha, a great excuse to play with the new math engine.
Wolfram|Alpha queries for “rain New Jersey June 200Y” are detailed and fascinating, showing temps, rain, cloud cover, humidity, and more, complete with graphs (hint: click “More”). But they don’t seem to directly answer how many days it rained at least some amount. The answer is displayed graphically but not numerically (the percentage and days of rain listed appears to be hours of rain divided by 24). Also, I didn’t see how to query multiple years at a time. So, in order to test whether 2009 was a record year, I would have to submit a separate query for each year (or bypass the web interface and use Mathematica directly). Still, Wolfram|Alpha does confirm that it rained 3.8 times as many hours in 2009 as 2008, already one of the wetter months on record.
WeatherBill, an endlessly configurable weather insurance service, more directly provided what I was looking for on one page. I asked for a price quote for a contract paying me $100 for every day it rains at least 0.1 inches in Newark, NJ during June 2010. It instantly spat back a price: $694.17.
It also reported how much the contract would have paid — the number of rainy days times $100 — every year from 1979 to 2008, on average $620 for 6.2 days. It said I could “expect” (meaning one standard deviation, or 68% confidence interval) between 3.9 and 8.5 days of rain in a typical year. (The difference between the average and the price is further confirmation that WeatherBill charges a 10% premium.)
Below is a plot of June rainy days in Newark, NJ from 1979 to 2009. (WeatherBill doesn’t yet report June 2009 data so I entered 12 as a conservative estimate based on info from Weather Underground.)
Indeed, our gloominess was justified: it rained in Newark more days in June 2009 than any other June dating back to 1979.
Intriguingly, our doominess may have been justified too. You don’t have to be a chartist to see an upward trend in rainy days over the past decade.
WeatherBill seems to assume as a baseline that past years are independent unbiased estimates of future years — usually not a bad assumption when it comes to weather. Still, if you believe the trend of increasing rain is real, either due to global warming or something else, WeatherBill offers a temptingly good bet. At $694.17, the contract (paying $100 per rainy day) would have earned a profit in 7 of the last 7 years. The chance of that streak being a coincidence is less than 1%.
If anyone places this bet, let me know. I would love to, but as of now I’m roughly $10 million in net worth short of qualifying as a WeatherBill trader.
“The No-Stats All-Star” is an entertaining, fascinating, and — warning — extremely long article by Michael Lewis in the New York Times Magazine on Shane Battier, a National Basketball Association player and Duke alumni whose intellectual and data-driven play fits perfectly into the Houston Rockets’s new emphasis on statistical modeling.
For Battier, every action is a numbers game, an attempt to maximize the probability of a good outcome. Any single outcome, good or bad, cannot be judged in isolation, as much as human nature desires it. Actions and outcomes have to be evaluated in aggregate.
Michael Lewis is a fantastic writer. Battier is an impressive player and an impressive person. Houston is not the first and certainly not the last sports team to turn to data as the arbiter of truth. This approach is destined to spread throughout industry and life, mostly because it’s right. (Yes, even for choosing shades of blue.)
WeatherBill let’s you construct an enormous variety of insurance contracts related to weather. For example, the screenshot embedded below shows how I might have insured my vacation at the New Jersey shore:
For $42.62 I could have arranged to be paid $100 per day of rain during my vacation.
(I didn’t actually purchase this mainly because the US government insists that I am a menace to myself and should not be allowed to enter into such a dangerous gamble — more on this later. And as Dan Reeves pointed out to me, it’s probably not rational to do for small sums.)
WeatherBill is an example of the evolution of financial exchanges as they embrace technology.
WeatherBill can be thought of as expressive insurance, a financial category no doubt poised for growth and a wonderful example of how computer science algorithms are finally supplanting the centuries-old exchange logic designed for humans (CombineNet is another great example).
WeatherBill can also be thought of as a combinatorial prediction market with an automated market maker, a viewpoint I’ll expand on now.
On WeatherBill, you piece together contracts by specifying a series of attributes: date range, place, type of weather, threshold temperature or participation level, minimum and maximum number of bad-weather days, etc. The user interface is extremely well done: a straightforward series of adaptive menu choices and text entry fields guide the customer through the selection process.
This flexibility quickly leads to a combinatorial explosion: given the choices on the site I’m sure the number of possible contracts you can construct runs into the millions.
Once you’ve defined when you want to be paid — according to whatever definition of bad weather makes sense for you or your business — you choose how much you want to be paid.
Finally, given all this information, WeatherBill quotes a price for your custom insurance contract, in effect the maximum amount you will lose if bad weather doesn’t materialize. Quotes are instantaneous — essentially WeatherBill is an automated market maker always willing to trade at some price on any of millions of contracts.
Side note: On WeatherBill, you control the magnitude of your bet by choosing how much you want to be paid. In a typical prediction market, you control magnitude by choosing how many shares to trade. In our own prediction market Yoopick, you control magnitude by choosing the maximum amount you are willing to lose. All three approaches are equivalent, and what’s best depends on context. I would argue that the WeatherBill and Yoopick approaches are simpler to understand, requiring less indirection. The WeatherBill approach seems most natural in an insurance context and the Yoopick approach in a gambling context.
How does the WeatherBill market maker determine prices? I don’t know the details, but their FAQ says that prices change “due to a number of factors, including WeatherBill forecast data, weather simulation, and recent Contract sales”. Certainly historical data plays an important role — in fact, with every price quote WeatherBill tells you what you would have been paid in years past. They allow contracts as few as four days into the future, so I imagine they incorporate current weather forecasts. And the FAQ implies that some form of market feedback occurs, raising prices on contract terms that are in high demand.
Interface is important. WeatherBill shows that a very complicated combinatorial market can be presented in a natural and intuitive way. Though greater expressiveness can mean greater complexity and confusion, Tuomas Sandholm is fond of pointing out that, when done right, expressiveness actually simplifies things by allowing users to speak in terms they are familiar with. WeatherBill — and to an extent Yoopick IMHO — are examples of this somewhat counterintuitive principle at work.
There is another quote from WeatherBill’s FAQ that alludes to an even higher degree of combinatorics coming soon:
Currently you can only price contracts based on one weather measurement. We’re working on making it possible to use more than one measurement, and hope to make it available soon.
If so, I can imagine the number of possible insurance contracts quickly growing into the billions or more with prices hinging on interdependencies among weather events.
Finally, back to the US government treating me like a child. It turns out that only a very limited set of people can buy contracts on WeatherBill, mainly businesses and multi-millionaires who aren’t speculators. In fact, the rules of who can play are a convoluted jumble that I believe are based on regulations from the US Commodity Futures Trading Commission.
Luckily, WeatherBill provides a nice “choose your own adventure” style navigation flow to determine whether you are allowed to participate. Most people will quickly find they are not eligible. (I don’t officially endorse the CYOA standard of re-starting over and over again until you pass.)
Even if red tape locks the average consumer out of direct access, clever companies are stepping in to mediate. In a nice intro piece on WeatherBill, Newsweek mentions that Priceline used WeatherBill to back a “Sunshine Guaranteed” promotion offering refunds to customers whose trips were rained out.
Can you think of other end-arounds to bring WeatherBill functionality to the masses? What other forms of expressive insurance would you like to see?
The reporter phrased prices in terms of the candidates’ percent chance of winning:
Traders … gave Democratic front-runner Barack Obama an 86 percent chance of being the Democratic presidential nominee, versus a 12.8 percent for Clinton…
…traders were betting the Democratic nominee would ultimately become president. They gave the Democrat a 59.1 percent chance of winning, versus a 48.8 percent chance for the Republican.
The latter numbers imply an embarrassingly incoherent market, giving the Democrats and Republicans together a 107.9% chance of winning. This is almost certainly the result of a typo, since the Republican candidate on intrade has not been much above 40 since mid 2007.
Still, typos aside, we know that the last-trade prices of candidates on intrade and IEM often don’t sum to exactly 100. So how should journalists report prediction market prices?
Byrne Hobart suggests they should stick to something strictly factual like "For $4.00, an investor could purchase a contract which would yield $10.00" if the Republican wins.
I disagree. I believe that phrasing prices as probabilities is desirable. The general public understands “percent chance” without further explanation, and interpreting prices in this way directly aligns with the prediction market industry’s message.
When converting prices to probabilities, is a journalist obligated to normalize them so they sum to 100? Should journalists report last-trade prices or bid-ask spreads or something else?
My inclination is that bid-ask spreads are better. Something like "traders gave the Democrats between a 22 and 30 percent chance of winning the state of Arkansas". These will rarely be inconsistent (otherwise arbitrage is sitting on the table) and the phrasing is still relatively easy to understand.
In measuring precipitation accuracy, the study assumed that if a forecaster predicted a 50 percent or higher chance of precipitation, they were saying it was more likely to rain than not. Less than 50 percent meant it was more likely to not rain.
That prediction was then compared to whether or not it actually did rain…
Often, predicting success is being a success. Witness Sequoia Capital or Warren Buffet.
In the media industry (e.g., books, celebs, movies, music, tv, web), predicting success largely boils down to predicting popularity.
Predicting popularity would be wonderfully easy, if it weren’t for one inconvenient truth: people herd. If only people were as fiercely independent as they sometimes claim to be — if everyone decided what they liked independently, without regard to what others said — then polling would be the only technology we would need. A small audience poll would foreshadow popularity with high accuracy.
Alas, such is not the case. No one consumes media in a vacuum. People are persuaded by influencers and influenced by persuaders. People respond in whole or in part to the counsel of critics, peers, viruses, and (yes) advertisers. So, what becomes popular is not simply a matter of what is good. What becomes popular depends on a complex dynamic process of spreading influence that’s hard to track and even harder to predict.
Columbia sociologist (and I’m happy to note future Yahoo) Duncan Watts and his colleagues conducted an artful study — described eloquently in the NY Times — asking just how much of media success reflects the true quality of the product, and how much is due to the quirks of social influence. In a series of carefully controlled experiments, the authors tease apart two distinct factors in a song’s ultimate success: (1) the inherent quality of the song, or the degree people like the song if presented it in isolation, and (2) dumb luck, or the extent the song happens by chance to get some of the best early buzz, snowballing it to the top of the charts in a self-fulfilling prophesy. Lo and behold, they found that, while inherent quality does matter, the luck of the draw plays at least as big a role in determining a song’s ultimate success.
If so, Big Media might be forgiven for their notoriously poor record of picking winners. Over and over, BM hoists on us stinkers like Gigli and stale knockoffs like Treasure Hunters. (In prediction lingo, these are false positives.) At the same time, BM snubbed (at least initially) some cultural institutions like Star Wars and Seinfeld. (False negatives.)
So, are media executives making the best of a bad situation, eking out as much signal as possible from an inherently noisy process? Or might some other institution yield forecasts with fewer false-atives?
I think you know where this is going. Prediction markets for media!
Media Predict is exactly that: a new prediction market aimed at forecasting media success. I’d like to congratulate founder Brent Stinski on a spectacular launch done right. Media Predict sprinted out of the gates with a deal with Simon & Schuster’s Touchstone Books and a companion piece in the NY Times, spawning coverage in The Economist and NPR. (Also congrats to Inkling Markets, the “powered by” provider.) More importantly, the website is clean, clear, complete (enough), and ready for launch.
The New York publishing world isridiculing Simon & Schuster for ceding its editorial power to the crowd. (In fact, S&S reserves the right to choose any book or none at all.)
Time will tell whether prediction markets can be better than (or at least more cost effective than) traditional media executives. One thing is for certain: one way or another, the power structure in the publishing world is changing rapidly and dramatically (no one sees and explains this better than Tim O’Reilly). My bet is that many artists and consumers will emerge feeling better than ever.
One of the purest and most fascinating examples of the “wisdom of crowds” in action comes courtesy of a unique online contest called ProbabilitySports run by mathematician Brian Galebach.
In the contest, each participant states how likely she thinks it is that a team will win a particular sporting event. For example, one contestant may give the Steelers a 62% chance of defeating the Seahawks on a given day; another may say that the Steelers have only a 44% chance of winning. Thousands of contestants give probability judgments for hundreds of events: for example, in 2004, 2,231 ProbabilityFootball participants each recorded probabilities for 267 US NFL Football games (15-16 games a week for 17 weeks).
An important aspect of the contest is that participants earn points according to the quadratic scoring rule, a scoring method designed to reward accurate probability judgments (participants maximize their expected score by reporting their best probability judgments). This makes ProbabilitySports one of the largest collections of incentivized1 probability judgments, an extremely interesting and valuable dataset from a research perspective.
The first striking aspect of this dataset is that most individual participants are very poor predictors. In 2004, the best score was 3747. Yet the average score was an abysmal -944 points, and the median score was -275. In fact, 1,298 out of 2,231 participants scored below zero. To put this in perspective, a hypothetical participant who does no work and always records the default prediction of “50% chance” for every team receives a score of 0. Almost 60% of the participants actually did worse than this by trying to be clever.
Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.
Yet something astonishing happens when we average together all of these participants’ poor and miscalibrated predictions. The “average predictor”, who simply reports the average of everyone else’s predictions as its own prediction, scores 3371 points, good enough to finish in 7th place out of 2,231 participants! (A similar effect can be seen in the 2003 ProbabilityFootball dataset as reported by Chen et al. and Servan-Schreiber et al.)
Even when we average together the very worst participants — those participants who actually scored below zero in the contest — the resulting predictions are amazingly good. This “average of bad predictors” scores an incredible 2717 points (ranking in 62nd place overall), far outstripping any of the individuals contributing to the average (the best of whom finished in 934th place), prompting someone in this audience to call the effect the “wisdom of fools”. The only explanation is that, although all these individuals are clearly prone to error, somehow their errors are roughly independent and so cancel each other out when averaged together.
Daniel Reeves and I follow up with a companion post on Robin Hanson’s OvercomingBias forum with some advice on how predictors can improve their probability judgments by averaging their own estimates with one or more others’ estimates.
In a related paper, Dani et al. search for an aggregation algorithm that reliably outperforms the simple average, with modest success.
   Â
1Actually the incentives aren’t quite ideal even in the ProbabilitySports contest, because only the top few competitors at the end of each week and each season win prizes. Participants’ optimal strategy in this all-or-nothing type of contest is not to maximize their expected score, but rather to maximize their expected prize money, a subtle but real difference that tends to induce greater risk taking, as Steven Levitt describes well. (It doesn’t matter whether participants finish in last place or just behind the winners, so anyone within striking distance might as well risk a huge drop in score for a small chance of vaulting into one of the winning positions.) Nonetheless, Wolfers and Zitzewitz show that, given the ProbabilitySports contest setup, maximizing expected prize money instead of expected score leads to only about a 1% difference in participants’ optimal probability reports.
Musings of a computer scientist on predictions, odds, and markets





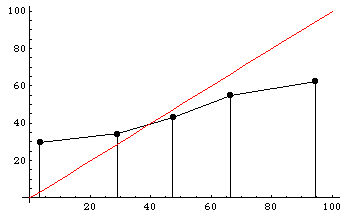 Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.
Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.