Often, predicting success is being a success. Witness Sequoia Capital or Warren Buffet.
In the media industry (e.g., books, celebs, movies, music, tv, web), predicting success largely boils down to predicting popularity.
Predicting popularity would be wonderfully easy, if it weren’t for one inconvenient truth: people herd. If only people were as fiercely independent as they sometimes claim to be — if everyone decided what they liked independently, without regard to what others said — then polling would be the only technology we would need. A small audience poll would foreshadow popularity with high accuracy.
Alas, such is not the case. No one consumes media in a vacuum. People are persuaded by influencers and influenced by persuaders. People respond in whole or in part to the counsel of critics, peers, viruses, and (yes) advertisers. So, what becomes popular is not simply a matter of what is good. What becomes popular depends on a complex dynamic process of spreading influence that’s hard to track and even harder to predict.
Columbia sociologist (and I’m happy to note future Yahoo) Duncan Watts and his colleagues conducted an artful study — described eloquently in the NY Times — asking just how much of media success reflects the true quality of the product, and how much is due to the quirks of social influence. In a series of carefully controlled experiments, the authors tease apart two distinct factors in a song’s ultimate success: (1) the inherent quality of the song, or the degree people like the song if presented it in isolation, and (2) dumb luck, or the extent the song happens by chance to get some of the best early buzz, snowballing it to the top of the charts in a self-fulfilling prophesy. Lo and behold, they found that, while inherent quality does matter, the luck of the draw plays at least as big a role in determining a song’s ultimate success.
If so, Big Media might be forgiven for their notoriously poor record of picking winners. Over and over, BM hoists on us stinkers like Gigli and stale knockoffs like Treasure Hunters. (In prediction lingo, these are false positives.) At the same time, BM snubbed (at least initially) some cultural institutions like Star Wars and Seinfeld. (False negatives.)
So, are media executives making the best of a bad situation, eking out as much signal as possible from an inherently noisy process? Or might some other institution yield forecasts with fewer false-atives?
I think you know where this is going. Prediction markets for media!
Media Predict is exactly that: a new prediction market aimed at forecasting media success. I’d like to congratulate founder Brent Stinski on a spectacular launch done right. Media Predict sprinted out of the gates with a deal with Simon & Schuster’s Touchstone Books and a companion piece in the NY Times, spawning coverage in The Economist and NPR. (Also congrats to Inkling Markets, the “powered by” provider.) More importantly, the website is clean, clear, complete (enough), and ready for launch.
I first met Brent Stinski in 2006 at Collabria’s NYC Prediction Markets Summit and his concept impressed me. Among the flury of recent play money PM startups, Media Predict’s business plan seems one of the most credible. The site taps simultaneously into the wisdom of crowds ethos, the user-generated content explosion, artists’ anti-establishment streak, and the public’s ambivalence toward Big Media. (The latter two factors are epitomized no more vehemently and eloquently than in an essay by Courtney Love, and stoke the fires of sites like Garage Band, Magnatune, Creative Commons, Lulu, Kinooga, and even MySpace, not to mention mashup fever, open source, anti-DRM-ism, etc.)
The New York publishing world is ridiculing Simon & Schuster for ceding its editorial power to the crowd. (In fact, S&S reserves the right to choose any book or none at all.)
Time will tell whether prediction markets can be better than (or at least more cost effective than) traditional media executives. One thing is for certain: one way or another, the power structure in the publishing world is changing rapidly and dramatically (no one sees and explains this better than Tim O’Reilly). My bet is that many artists and consumers will emerge feeling better than ever.




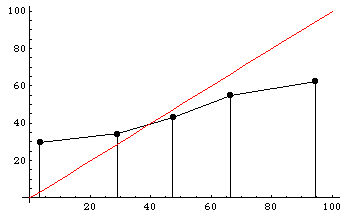 Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.
Participants are also poorly calibrated. To the right is a histogram dividing participants’ predictions into five regions: 0-20%, 20-40%, 40-60%, 60-80%, and 80-100%. The y-axis shows the actual winning percentages of NFL teams within each region. Calibrated predictions would fall roughly along the x=y diagonal line, shown in red. As you can see, participants tended to voice much more extreme predictions than they should have: teams that they said had a less than 20% chance of winning actually won almost 30% of the time, and teams that they said had a greater than 80% chance of winning actually won only about 60% of the time.